
Kimi Team K2 技术报告
摘要
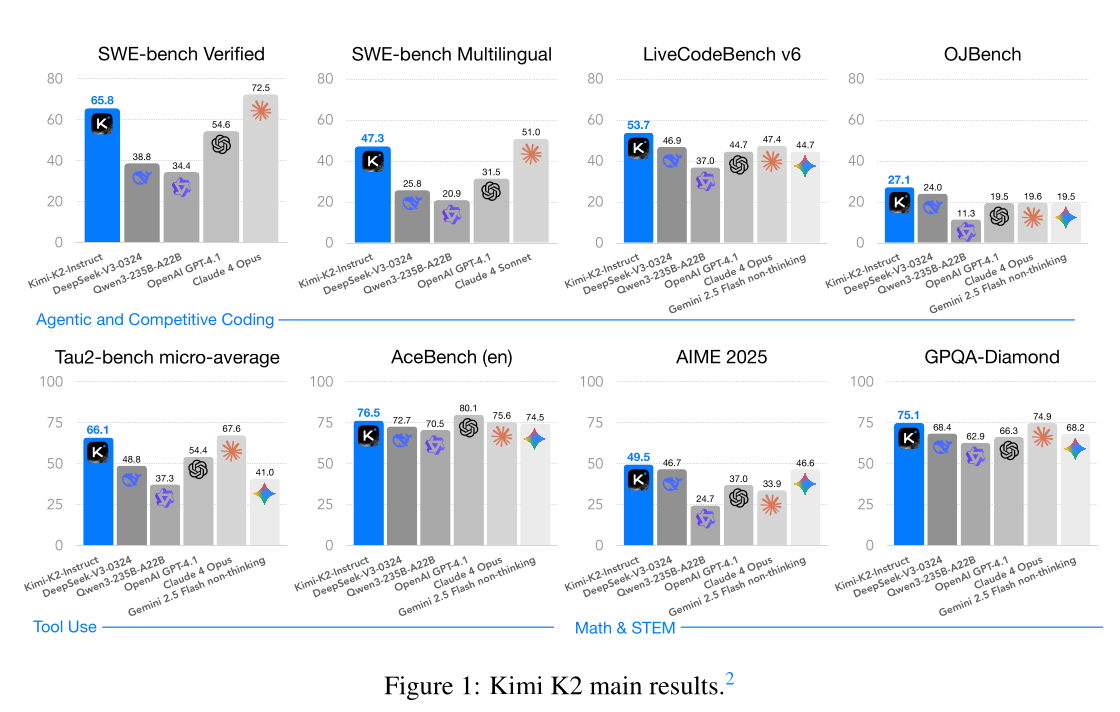
我们介绍Kimi K2,一种混合专家(MoE)大语言模型,拥有320亿激活参数和1万亿总参数。我们提出了MuonClip优化器,该优化器在Muon的基础上进行改进,采用了一种新颖的QK-clip技术来解决训练不稳定性问题,同时保留了Muon的高级token效率。基于MuonClip,K2在155亿个token上进行了预训练,且未出现任何损失峰值。在后训练阶段,K2经历了多阶段后训练过程,其中包括大规模智能体数据合成管道和联合强化学习(RL)阶段,通过与真实和合成环境的交互,模型提升了其能力。Kimi K2在开源非思考模型中达到了最先进的性能,尤其在智能体能力方面表现出色。值得注意的是,K2在Tau2-Bench上获得66.1分,在ACEBench(英文)上获得76.5分,在SWE-Bench Verified上获得65.8分,在SWE-Bench Multilingual上获得47.3分——在非思考环境下超越了大多数开源和闭源基线模型。它在编码、数学和推理任务中也展现了强大的能力,在LiveCodeBench v6上得分53.7,在AIME 2025上得分49.5,在GPQA-Diamond上得分75.1,在OJBench上得分27.1,且均未使用扩展思考。这些结果使Kimi K2成为迄今为止最强大的开源大语言模型之一,特别是在软件工程和智能体任务方面。我们发布了基础模型和后训练模型检查点,以促进未来智能体智能的研究和应用。
在大模型训练中,Muon 是一种新型优化器,它的目标是提升训练效率和稳定性,尤其在参数量巨大的语言模型中表现出色。QK-clip 是 Kimi K2 独有的机制,目前主要作为其 MuonClip 优化器的一部分,用于解决超大规模模型训练中的注意力数值爆炸问题。
- 在 QK-clip 中,QK 并不是传统意义上的“键值对”,而是指注意力机制中的 Query(Q)和 Key(K)矩阵 的乘积,也就是计算注意力 logits 的核心部分
- 对每个注意力头计算 QK 的最大值(即最大 attention logit)
- 如果超过设定阈值(如 $ τ $ = 100),就对对应的权重矩阵进行缩放
- 缩放因子为: $ \gamma = \frac{\tau}{S_{\text{max}}^h} $
- 其中 $ {S_{\text{max}}^h} $ 是第 h 个注意力头的最大 QK 值
引言
大语言模型(LLMs)的开发正在经历一场深刻的范式转变,朝向智能体智能(Agentic Intelligence)发展——即模型在复杂且动态的环境中自主感知、规划、推理和行动的能力。这种转变标志着从静态模仿学习向主动通过交互学习、获取超出训练分布的新技能、并通过经验适应行为的模型的转变。据信,这种方法使人工智能体能够超越静态人类生成数据的限制,通过自身的探索和利用获得超人类能力。因此,智能体智能正迅速成为下一代基础模型的定义性能力,对工具使用、软件开发和现实世界的自主性产生广泛影响。
实现智能体智能在预训练和后训练阶段都带来了挑战。预训练必须在有限高质量数据的约束下,为模型赋予广泛的通用先验知识,同时提升token效率——每个token的学习信号——作为一个关键的扩展系数。后训练必须将这些先验知识转化为可执行的行为,然而,多步骤推理、长期规划和工具使用等智能体能力在自然数据中很少见,且扩展成本高昂。可扩展地合成结构化、高质量的智能体轨迹,结合融入偏好和自我批评的通用强化学习(RL)技术,是弥合这一差距的关键。
在这项工作中,我们介绍了Kimi K2,一种拥有1.04万亿参数的混合专家(MoE)大语言模型,其中激活参数为320亿,专门设计来应对核心挑战并推动智能体能力的边界。我们的贡献涵盖了预训练和后训练两个前沿领域:
- 我们提出了MuonClip,一种新颖的优化器,它将高效的Muon算法与一种增强稳定性的机制QK-Clip相结合。使用MuonClip,我们成功地在155亿个token上对Kimi K2进行了预训练,且未出现任何损失峰值。
- 我们引入了一个大规模智能体数据合成管道,通过模拟和现实世界环境系统性地生成工具使用演示。该系统构建了多样化的工具、智能体、任务和轨迹,以大规模创建高保真、经验证正确的智能体交互。
- 我们设计了一个通用的强化学习框架,结合了可验证奖励(RLVR)与自我批评评分奖励机制。该模型不仅从外部定义的任务中学习,还通过评估自身输出进行学习,将对齐从静态领域扩展到开放式领域。
Kimi K2 在广泛的智能体和前沿基准测试中表现出色。它在 Tau2-bench 上获得 66.1 分,在 ACEBench(英文)上获得 76.5 分,在 SWE-bench Verified 上获得 65.8 分,在 SWE-bench Multilingual 上获得 47.3 分,在非思考评估设置下超越了大多数开源和闭源基线模型,缩小了与 Claude 4 Opus 和 Sonnet 的差距。在编码、数学和更广泛的 STEM 领域,Kimi K2 在 LiveCodeBench v6 上获得 53.7 分,在 OJBench 上获得 27.1 分,在 AIME 2025 上获得 49.5 分,在 GPQA-Diamond 上获得 75.1 分,进一步凸显了其在通用任务中的能力。在 LMSYS Arena 排行榜(2025 年 7 月 17 日)上,Kimi K2 基于超过 3000 次用户投票,位列开源模型第一,总排名第五。
为了推动智能体智能的进一步发展,我们将开源我们的基础模型和后训练检查点,使社区能够大规模地探索、优化和部署智能体智能。
预训练
Kimi K2的基础模型是一个万亿参数的混合专家(MoE)Transformer模型[72],在155亿个高质量token上进行了预训练。鉴于高质量人类数据的可用性日益有限,我们提出token效率正成为大语言模型扩展中的关键系数。为解决这一问题,我们引入了一系列专门为最大化token效率设计的预训练技术。具体来说,我们采用了高效的Muon优化器[33, 46],并通过引入QK-Clip缓解其训练不稳定性。此外,我们还结合了合成数据生成技术,进一步从可用高质量token中榨取智能。模型架构采用了类似DeepSeek-V3 [10]的超稀疏MoE,结合多头潜在注意力(MLA),这一设计源于经验性扩展法则分析。底层基础设施旨在优化训练效率和研究效率。
MuonClip:通过权重裁剪实现稳定训练
我们使用高效的Muon优化器[33]训练Kimi K2,结合了权重衰减和一致性更新RMS缩放[46]。我们在之前的Moonlight工作[46]中的实验表明,在相同的计算预算和模型规模(因此也是相同的训练数据量)下,Muon显著优于AdamW[36, 48],使其成为提升大语言模型训练中token效率的有效选择。
Muon训练在扩展时的不稳定性:尽管Muon具有高效性,但扩展Muon训练揭示了一个挑战:由于注意力logits的爆炸性增长导致的训练不稳定性,这一问题在我们的实验中在使用Muon时更频繁,而在使用AdamW时较少。现有的缓解策略不足。例如,logit软上限[69]直接裁剪注意力logits,但查询和键之间的点积在应用上限之前仍可能过度增长。另一方面,查询-键归一化(QK-Norm)[11, 81]不适用于多头潜在注意力(MLA),因为其键矩阵在推理过程中并非完全实现。
使用QK-Clip驯服Muon:为解决这一问题,我们提出了一种新颖的权重裁剪机制QK-Clip,以明确约束注意力logits。QK-Clip通过在更新后重新缩放查询和键投影权重来限制注意力logits的增长。
设Transformer层的输入表示为X。对于每个注意力头h,其查询、键和值投影的计算方式如下:
$$ Q^h = XW_q^h,\quad K^h = XW_k^h,\quad V^h = XW_u^h $$
其中 $ W_q,W_k,W_u $ 是模型参数。注意力输出为:
$$ O^h = softmax(\frac{1}{\sqrt{d}} Q^h K^{hT})V^h $$
我们将最大logit定义为每个注意力头的标量,表示该批次B中softmax的最大输入:
$$ S^h_{max} = \frac{1}{\sqrt{d}} \max\limits_{x \in B} \max\limits_{i,j} Q^h_i K^{hT}_j $$
其中 $ i, j $ 是训练样本 $ X $ 中不同 token 的索引。
QK-Clip 的核心思想是每当 $ S^h_{max} $ 超过目标阈值 $ τ $ 时,对 $ W_k $ 和 $ W_q $ 进行重新缩放。重要的是,这一操作不会改变当前步骤的前向/后向计算——我们仅使用最大 logit 作为指导信号,以确定控制权重增长的强度。
一个简单的实现方法是同时对所有注意力头进行裁剪:
$$ W^h_q \leftarrow \gamma^\alpha W^h_q \quad W^h_k \leftarrow \gamma^{1-\alpha} W^h_k $$
其中 $ {\gamma} $ = $ min(1, τ / S_{max}) $,$ S_{max} = max_h $ $ S^h_{max} $,α 是一个平衡参数,通常设置为 0.5,对查询和键应用相同的缩放。
然而,我们观察到在实践中,只有少数注意力头表现出logits爆炸。为了尽量减少对模型训练的干预,我们为每个注意力头确定一个缩放因子 $ γh = min(1, τ / S^h_{max}) $,并选择应用逐头QK-Clip。对于常规多头注意力(MHA),这种裁剪是直接的。对于多头潜在注意力(MLA),我们仅对非共享的注意力头组件应用裁剪:
- $ q^C $ 和 $ k^C $(特定于注意力头的组件):每个都按 $ \sqrt{\gamma_h} $ 进行缩放
- $ q^R $(特定于注意力头的旋转):按 $ γh $ 进行缩放
- $ k^R $(共享旋转):保持不变,以避免对不同注意力头的影响。
MuonClip:新型优化器 我们将 Muon 与权重衰减、一致的 RMS 匹配和 QK-Clip 整合成一个单一的优化器,我们称之为 MuonClip(见 Algorithm 1)。
我们通过多项扩展实验展示了 MuonClip 的有效性。首先,我们使用原始 Muon 训练了一个中等规模的 90 亿激活参数和 530 亿总参数的混合专家(MoE)模型。如图 2(左)所示,我们观察到最大注意力 logits 很快超过 1000 的幅度,表明在这种规模的 Muon 训练中,注意力 logits 爆炸问题已经很明显。这一水平的 max logits 通常会导致训练不稳定,包括显著的损失峰值和偶尔的发散。
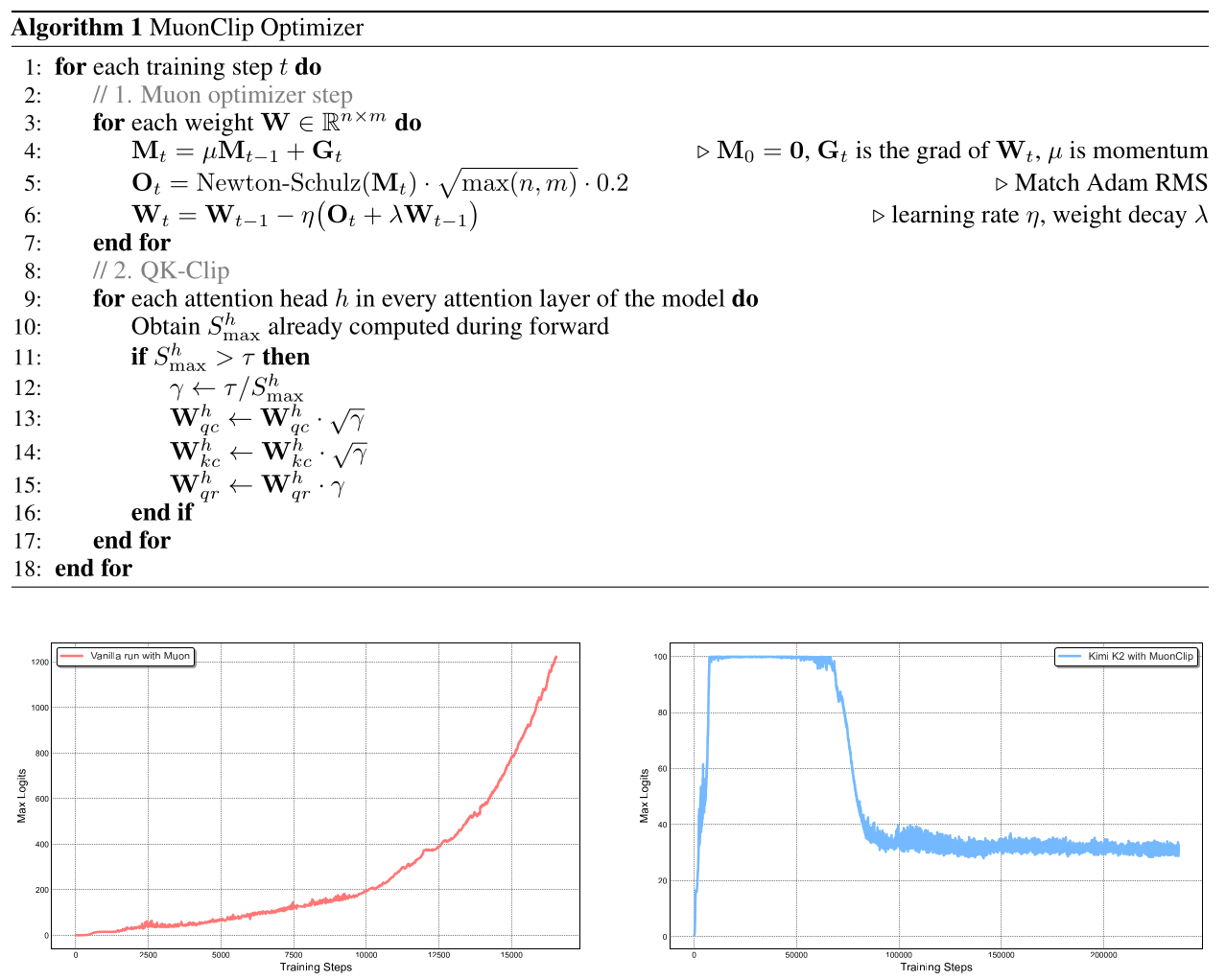
图2:左图:在中等规模的训练过程中,注意力 logits 迅速超过 1000,这可能导致潜在的数值不稳定性甚至训练发散。右图:Kimi K2 使用 MuonClip 和 $ τ $ = 100 在整个训练过程中的最大 logits。最大 logits 迅速增加到上限值 100,并且在约 30% 的训练步骤后才衰减到稳定范围,展示了 QK-Clip 的有效调控效果。
接下来,我们证明了 QK-Clip 不会降低模型性能,并确认 MuonClip 优化器在不负面影响损失轨迹的情况下,保留了 Muon 的优化特性。实验设计和结果的详细讨论见附录 D。
最后,我们使用 MuonClip($ τ $ = 100)训练了大规模 MoE 模型 Kimi K2,并在整个训练过程中监控最大注意力 logits(图2(右))。最初,由于 QK-Clip 的作用,logits 被限制在 100。随着训练的进行,最大 logits 逐渐衰减到典型的运行范围,无需对 $ τ $ 进行任何调整。重要的是,如图3 所示,训练损失保持平滑和稳定,没有观察到任何峰值,这验证了 MuonClip 在大规模语言模型训练中对注意力动态提供了稳健且可扩展的控制。