
在多GPU系统上分配和部署大型语言模型的难点
现代大型语言模型(LLMs),特别是基于Transformer架构的模型,其指数级的规模增长已经超出了单个GPU的内存和计算能力。这使得将大型模型分布到多个GPU上成为必要。在这些多GPU设置中,每个GPU管理特定的参数子集和计算任务,从而实现有效的并行化和分布式训练。
多GPU大型语言模型训练:模型分割、并行化和开销
多GPU大型语言模型训练的主要难点在于高效地分割和同步跨GPU的庞大模型参数、激活值和梯度,以确保分布式计算的连贯性和有效性。

图11展示了基于Transformer模型的GPU间分区策略和张量同步,强调了自注意力机制和前馈神经网络(FFN)计算输出的频繁交换。Transformer架构中的自注意力机制计算序列中所有token(标记)之间的交互。乍看之下,似乎GPU需要生成并交换部分查询(query)、键(key)和值(value)向量。然而,通过多头注意力(multi-head attention)和分组查询注意力(grouped query attention),每个GPU可以仅使用其分配的部分向量独立计算自注意力,这些机制将一个大型注意力层分割为多个并行的小层。尽管如此,定期同步这些计算得到的向量及其梯度仍是必要的,以确保分布式架构中全局的一致性和连贯性。这一同步步骤对于精确的梯度计算和参数更新至关重要,显著增加了GPU间通信带宽和内存资源的需求。
除了自注意力机制,Transformer架构还包括前馈神经网络(FFN)层,这些层支持独立的标记级计算。虽然FFN操作允许并行执行,但在前向和反向传播过程中,仍然需要在GPU间交换中间结果和同步梯度。这种梯度同步需要频繁交换中间梯度更新,进一步增加了GPU间通信的开销。
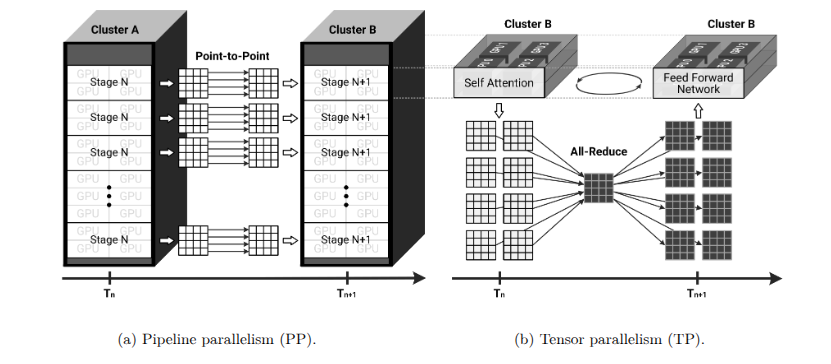
先进的并行化技术,如流水线并行(pipeline parallelism)和张量并行(tensor parallelism ),在分布式大型语言模型(LLM)训练中也扮演着关键角色。图12a通过展示模型执行的顺序“stages(阶段)”来可视化流水线并行,说明了每个GPU集群如何处理Transformer模型的特定层以优化资源利用率。流水线并行将Transformer模型划分为顺序阶段,每个阶段由独立的GPU集群处理。尽管这种方法增加了可用的并行计算能力,但需要精心编排以最小化由于阶段间数据依赖性导致的空闲周期(流水线气泡)。各阶段必须同步数据交接以确保流畅运行和GPU资源的最大利用率。流水线并行对于大型模型尤其有效,因为每个阶段的计算可以充分利用单个GPU的性能。
另一方面,张量并行通过将大型张量操作(如矩阵乘法)分割到多个GPU上,与流水线并行形成互补。这种方法能够在层内实现同步计算,加速大型张量操作的处理。然而,张量并行需要频繁同步GPU之间的部分结果,通常使用如All-Reduce、All-Gather和Reduce-Scatter等集体通信(collective communication )操作。这些集体通信操作使GPU能够交换和聚合中间计算结果,保持并行计算的一致性。图12b进一步展示了张量并行,通过描述大型张量计算如何分布到多个GPU上,强调了集体通信操作在同步部分计算中的关键作用。因此,张量并行的有效实现依赖于优化的集体通信算法和高性能互连基础设施,以保持低通信延迟和高吞吐量。
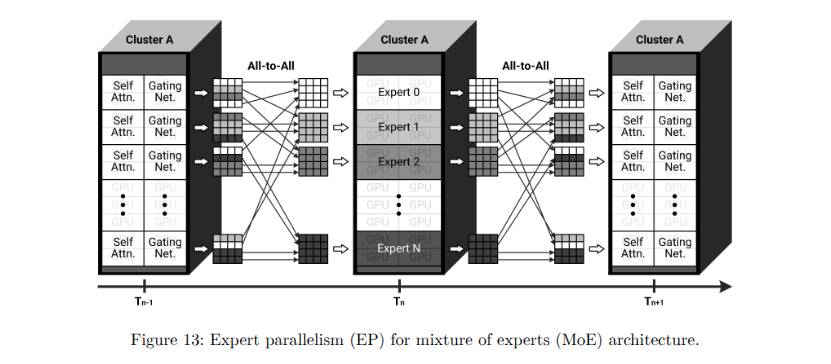
此外,采用动态计算策略,如混合专家(MoE)架构,为训练工作流程增加了复杂性。图13展示了MoE专家模块在GPU上的分布,强调了每个GPU如何独立管理不同的数据计算子集。MoE模型将网络划分为多个专家模块,每个模块托管在专用GPU或GPU集群上。每个GPU作为一个独立专家,为特定输入数据子集执行不同的前向和反向计算。输入数据序列(以标记形式表示)根据预定标准或路由策略分发到多个GPU上。代表句子或查询部分的标记或标记段根据模型的专家选择策略分配到相应的GPU。在标记分配完成后,每个GPU专家独立处理其指定的计算任务。然而,基于Transformer的模型需要聚合同多个专家的输出以生成有意义的预测,这导致GPU之间“频繁交换”中间结果。该图展示了MoE架构中GPU之间的聚合和同步过程,突显了为保持全局模型一致性所需的密集中间计算结果交换。定期聚合和同步专家之间的梯度对于维持全局模型一致性至关重要。因此,MoE训练显著增加了GPU间通信需求,需要复杂的高带宽、低延迟互连基础设施。
多GPU大型语言模型推理:优化技术与难点
与训练阶段相比,推理阶段主要以计算速度和实时响应性为重点。然而,近期针对推理工作负载的优化技术已将性能重点从单纯的计算能力部分转向增加内存容量和GPU间通信带宽。这些转变源于旨在减少冗余计算和提升上下文准确性的高级方法,同时引入了显著的系统级新挑战。
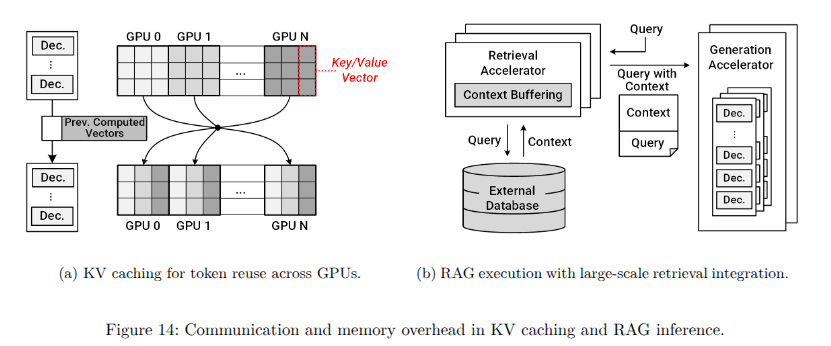
图14a和图14b分别展示了推理优化技术(如KV缓存和RAG)的GPU间通信和外部数据访问模式。如图14a所示,KV缓存通过将之前计算的键和值向量直接存储在GPU内存中,体现了这种性能重点的转变。虽然该技术减少了冗余计算,显著加快了推理速度,但它大幅增加了GPU内存需求。随着模型和上下文窗口的规模扩大,KV缓存变得非常庞大,通常需要仔细分区并在GPU间进行频繁同步。因此,这对内存管理策略施加了巨大压力,并显著增加了GPU间通信开销,以维持缓存一致性和效率。
另一方面,如图14b所示,检索增强生成(RAG)进一步加剧了对内存和通信资源的需求。通过将外部知识库融入推理过程,RAG提高了输出的准确性和上下文相关性。然而,它要求GPU执行快速、频繁的外部数据库查询,迅速检索相关数据,并将这些外部信息无缝整合到正在进行的计算中。这些操作大幅增加了内存使用量以临时存储检索到的数据,同时对网络带宽和低延迟通信基础设施提出了更高的要求,从而使系统设计和性能优化变得更加复杂。
需要注意的是,自回归推理方法还带来了额外的内存和互连相关约束。由于标记生成固有的顺序依赖性,每个预测都明确依赖于之前生成的标记,严重限制了并行执行。因此,GPU必须尽快交换中间计算结果,并在推理步骤中保持同步。这种顺序依赖性不仅限制了可实现的并行度,还增加了GPU间通信流量,从而加剧了对低延迟和高吞吐量网络连接以及复杂内存管理解决方案的需求,以减少GPU空闲时间。
综合考虑这些因素,现代大型语言模型(LLM)的训练和推理工作负载越来越强调内存容量和GPU间通信基础设施。训练需要复杂的模型分区、频繁的同步以及先进的并行化技术,因为参数和激活值的大小超出了GPU的内存容量。类似地,推理优化技术如KV缓存、RAG和自回归方法虽然减少了冗余计算,但进一步放大了内存使用量和GPU间同步开销。因此,现代AI基础设施必须采用灵活的架构,不仅要高效管理内存和通信资源,还要满足计算性能需求,以应对当代LLM工作负载的全面需求。
多GPU系统的扩展:纵向增强与横向扩展
解决多GPU训练和推理中的GPU间通信挑战需要复杂的硬件互连和网络解决方案,以适应不同的性能和可扩展性要求。通常采用两种主要的架构策略:纵向扩展和横向扩展,来应对这些不同的操作场景。一般来说,纵向扩展架构使用高速“互连”技术,如NVLink、NVLink Fusion、UALink和CXL,而横向扩展架构则采用高带宽的“长距离网络”,如Ethernet或InfiniBand。
纵向扩展架构:高速直接互连
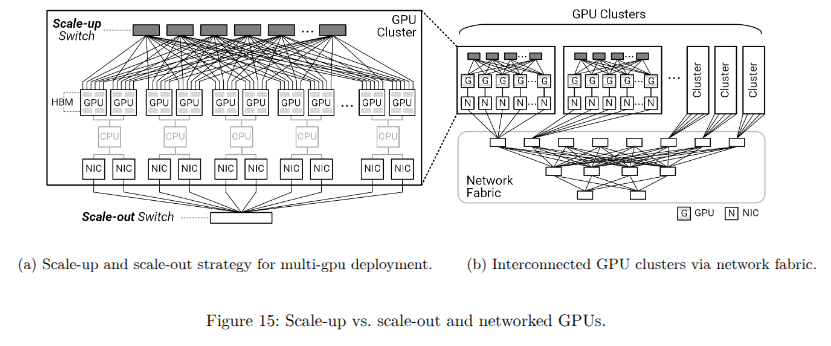
图15a比较了多GPU部署中的纵向扩展和横向扩展GPU互连架构。纵向扩展策略通过使用专有的高速、面向加速器的互连技术,将数量有限的GPU紧密耦合。这些直接的高带宽连接优化了数据传输效率,特别适合涉及频繁且密集数据交换的工作负载,例如在紧密集成的GPU集群中。纵向扩展解决方案对于需要最大节点内通信速度和最小延迟的任务具有优势,从而显著提升计算密集型场景的性能,如训练、实时推理和GPU密集型AI操作。
在大型语言模型(LLM)和最新一代数据中心架构出现之前,需要紧密集成的直接互连的GPU数量是有限的。然而,随着模型复杂性增加和数据量显著增长,需要这种连接的GPU数量呈指数级上升。此外,许多针对LLM的优化技术现在需要高速、低延迟的数据交换和一致的I/O数据共享。因此,现代数据中心呈现出一种趋势,即在每个机架中部署更多GPU,以提高计算效率、减少通信开销并降低TCO(总拥有成本)。例如,NVIDIA推出了一种新架构,采用专为高密度GPU部署设计的紧凑型液冷节点单元。这些节点利用高速NVLink和NVSwitch互连技术,将每个机架最多紧密集成72个GPU。这种直接互连设计提升了计算吞吐量,优化了GPU间通信效率,改善了热管理,从而降低了运营复杂性并进一步降低了TCO。
横向扩展架构:长距离网络接口
相比之下,横向扩展方法专为大规模数据中心部署设计,可能涉及分布在多个机架或节点上的数千个GPU。这种策略支持更广泛的可扩展性和更灵活的资源管理。横向扩展架构主要利用“长距离”基于网络的结构,依赖NICs(网卡)和支持RDMA的通信协议来实现GPU间的交互。如图15b所示,GPU被组织成通过网络结构互连的集群,从而实现模块化和动态的系统配置。
虽然长距离网络结构提供了出色的可扩展性、灵活性和潜在的更高聚合带宽,但不幸的是,它们也带来了额外的开销。这种开销源于复杂的硬件设计、精密的网络协议和软件介导的通信。具体来说,与紧密耦合的基于硬件的纵向扩展架构相比,数据序列化和反序列化、网络协议处理以及软件层面交互显著增加了通信延迟。因此,在设计大规模分布式AI系统时,仔细评估纵向扩展与横向扩展架构之间的权衡至关重要,以确保有效实现性能和效率目标。
另一方面,在以GPU为中心的AI基础设施中,无论是纵向扩展还是横向扩展系统,CPU仍然扮演着至关重要的支持角色。虽然GPU处理主要的计算任务,但CPU提供系统编排能力,管理GPU协调、数据传输和网络接口。因此,每个GPU或GPU集群都将一个或多个CPU和NICs(网卡)作为基本组件。一直以来,虽然对资源解耦方法有多种尝试。然而,完整的物理资源解耦尚未完全实现,因为CPU需要作为主机处理器,管理直接与GPU或加速器交互的总线接口和内存控制器。相反,近期行业趋势强调在单个节点内进行更紧密的集成或采用模块化扩展方法。NVIDIA的最新GPU模型(Grace Blackwell)是一个节点级集成的典型示例。