
接上一篇《LLM学习之路-从RNN到Transformer 2》
从Transformer到大型语言模型
Transformers的引入标志着序列建模的一次关键转变,它用可并行化的自注意力机制取代了RNN中的循环计算。这一创新使模型能够同时分析序列中所有标记之间的关系,加快了计算速度,并支持更深、更复杂的神经网络架构的开发。这一转变也成为GPU等硬件加速器广泛采用的关键转折点,因为其底层计算模式与大规模并行硬件高度契合。
大规模训练与参数优化
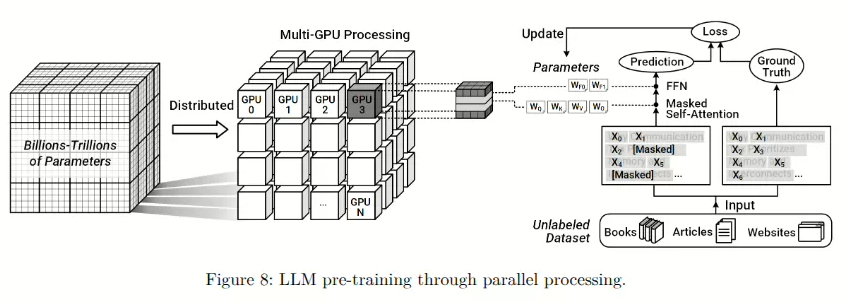
基于Transformer的可扩展性,研究人员开发了大型语言模型(LLMs),通过增加参数数量并在大规模、多样化的数据集上进行广泛训练,扩展了模型的能力。现代大型语言模型,如GPT-4 Turbo和谷歌的Gemini,可以包含数十亿甚至数万亿个参数。这些参数是神经网络层的可调整内部设置,在一个全面的预训练阶段通过大量的文本数据进行优化,这些数据包括书籍、学术文章、网站内容以及社交媒体内容。这种预训练通常采用自监督学习,这种方法使模型能够从无标签数据中自动获取有意义的表示。通常,这涉及到从给定上下文中预测被遮掩的单词、句子或片段。如图8所示,通过大量的预训练,LLMs将语言知识、语境理解、句法和语义的细微差别以及一般世界知识直接编码到模型的内部参数中,特别是在自注意力机制(查询、键和值向量)和前馈神经网络层(权重和偏置)中。
需要注意的是,训练大型语言模型(LLMs)需要大量的计算和多个GPU的并行处理。这些需求随着优化技术(如混合精度算术、跨多个节点的分布式训练以及复杂的梯度同步)的应用而进一步增加。Transformer的并行结构通过并行处理多个GPU集群上的大型参数集和海量数据集来解决这些问题。与之前受限于循环操作的顺序模型不同,Transformer充分利用了现代并行处理硬件,实现了可扩展的训练。然而,使用多个GPU进行大规模训练通常需要连续运行数周甚至数月的时间。这种漫长的训练时间源于巨大的内存需求以及GPU之间频繁的数据同步,突显了与可扩展性、内存容量以及互连设计相关的基础设施挑战。
确保连贯性与泛化性
许多现代的大语言模型在训练和推理过程中采用了自回归方法。自回归方法通过依次预测每个 token,且仅基于之前生成的 token 进行预测,从而捕捉语言数据中内在的顺序依赖关系。具体来说,在生成一个句子时,模型仅使用先前的上下文来确定每个单词,而不结合来自后续 token 的信息。这一特性使得自回归方法即使在缺乏未来上下文的情况下,仍能保持逻辑上的连贯性和上下文的准确性。
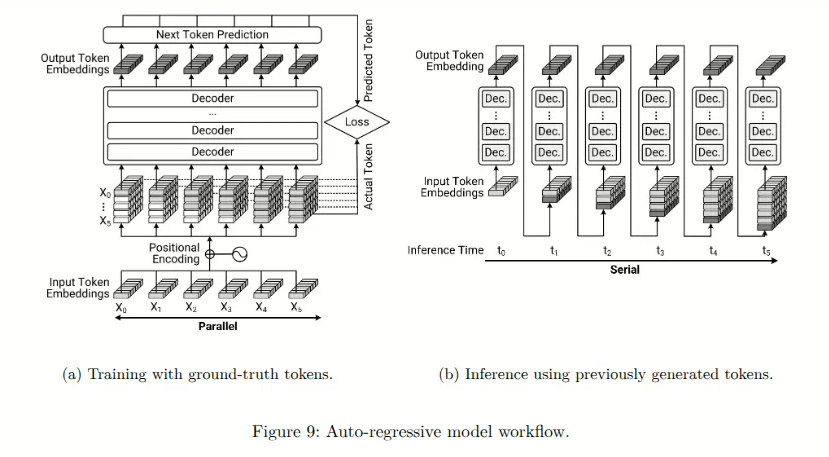
图9a展示了训练过程,在该过程中,模型学习根据提供序列中的前序标记来预测下一个标记。这种顺序方法帮助模型学习语法、句法和逻辑推进的模式,建模时间依赖关系并保持生成文本的连贯性。在推理过程中,如图9b所示,自回归模型一次生成一个标记。每个新标记随后成为后续预测的上下文的一部分。虽然这种顺序机制确保了输出的一致性和上下文的连贯性,但它限制了并行计算,相对于并行化生成方法降低了推理速度。
尽管存在这些计算限制,自回归模型仍然被广泛使用,因为它已被证明能够表示复杂的语言依赖关系并产生准确的输出,这对于高质量的语言生成任务至关重要。为了缓解推理能力的限制,现代的大语言模型还强调其广泛的预训练和强大的泛化能力。通过从大规模、多样化的文本数据集中学习,这些模型形成了全面的内部语言表示,使其能够灵活应用于各种下游任务,往往只需极少甚至无需额外的专门训练,这种情况被称为zero-shot(零样本)或few-shot(少样本)学习。这种泛化能力扩展了大型语言模型的应用范围,使其超越了传统的语言任务,进入了多模态领域,包括图像生成、视频合成、音频处理以及交互式对话系统等。
减少冗余并提高大型语言模型推理的可靠性
随着大型语言模型(LLMs)在各种应用中的广泛部署,两种关键技术:Key-Value键值(KV)缓存和Retrieval-Augmented Generation 检索增强生成(RAG)。已经被开发出来,以克服LLM推理过程中面临的重大计算和准确性相关的挑战。
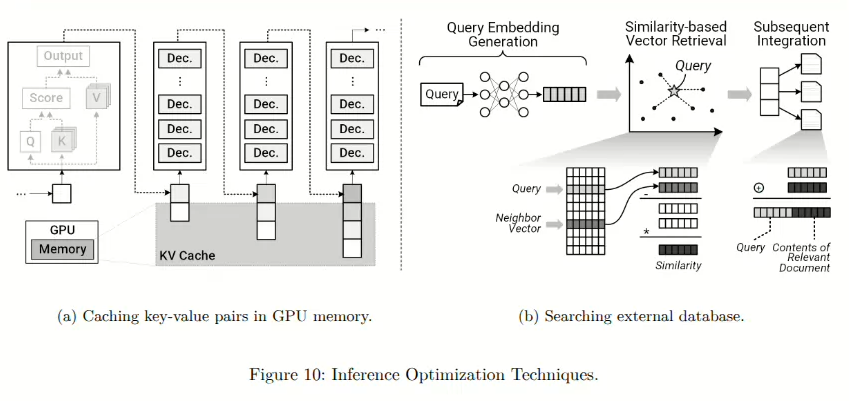
KV缓存解决了大型语言模型(LLM)自注意力机制中固有的计算效率低下的问题。由于采用自回归推理方法,每个 token 的生成依赖于之前生成的 token,LLM 必须在每个生成步骤重复计算涉及所有之前处理过的 token 的自注意力分数。如果没有优化,这将导致冗余和重复的计算,减慢推理速度。如图10a所示,KV缓存通过在初始计算后将计算得到的注意力分数作为键值对直接存储在GPU内存中来解决这个问题。一旦存储,这些缓存结果可以在后续的推理步骤中直接重复使用,而无需额外的计算。这可以减少冗余的计算开销,并加速推理过程,特别是对于较长的输入序列。然而,这种效率的提高是以增加内存需求为代价的。根据模型大小、token长度和推理复杂度的不同,KV缓存可能会占用30%到85%的可用GPU内存,显著加剧内存使用,并经常超过单个GPU模块的容量。
另一方面,RAG(检索-增强生成)针对的是大语言模型(LLM)的固有局限性,即模型幻觉问题。模型幻觉指的是模型生成的输出看似合理,但在事实上不正确或与上下文无关的情况。这种不准确性之所以产生,是因为LLM完全依赖于训练阶段学到的内部知识,缺乏实时或更新的外部上下文信息。RAG通过将外部知识检索直接整合到推理工作流中来提高模型的可靠性。当接收到输入查询时,配备了RAG的LLM首先会在一个外部知识数据库中搜索与上下文相关的信息,该数据库通常实现为专门的向量数据库或检索系统,如图10b所示。检索到的上下文信息随后与原始输入查询相结合,为模型生成最终响应提供准确的、经过外部验证的信息。尽管这可以减少幻觉并提高事实准确性,但它引入了额外的计算步骤,包括查询嵌入的生成、基于相似度的向量检索,以及将检索到的信息整合到推理过程中的后续步骤。因此,RAG增加了计算复杂性,并且需要大量的内存容量来维护大规模的向量数据库。此外,网络延迟和带宽成为影响性能的关键因素,因为从外部来源快速且可靠的检索直接影响到响应的准确性和推理的延迟。
需要注意的是,KV缓存和RAG对于解决大型语言模型(LLM)推理中的关键瓶颈都是至关重要的。KV缓存通过最小化自注意力机制中的冗余计算来优化推理速度,而RAG则通过利用外部知识源来提高输出结果的可靠性和准确性。尽管这些技术具有诸多优势,但在LLM中部署这些推理技术会增加对GPU内存、计算资源、网络带宽和存储基础设施的需求,这进一步强调了构建高度可扩展和可组合的数据中心架构的必要性,以支持多样化和密集的LLM工作负载要求。