
接上一篇《LLM学习之路-从RNN到Transformer 1》
从递归到并行性:Transformer的变革
2017年,随着Transformer架构的引入,序列建模取得了重大突破,这标志着彻底脱离了RNN和传统Seq2Seq模型中固有的递归计算结构。Transformer完全放弃了递归,采用了一种完全基于注意力(attention)的设计。特别是,Transformer利用了自注意力机制(self-attention),它能够同时计算序列中所有位置之间的交互。与嵌入在RNN中的传统注意力机制不同,自注意力机制可以并行独立地计算所有序列位置的注意力分数,而不依赖于先前计算的状态或位置之间的顺序依赖。这种独立性源于每个位置的注意力计算直接基于固定的输入表示,即嵌入(embeddings)。通过消除顺序处理的限制,Transformer能够充分利用现代并行处理硬件,从而提升计算效率和可扩展性。
这种并行处理能力是由Transformer的嵌入层实现的,这些嵌入层将离散的标记投影到高维连续向量空间中。如图5b所示,这些嵌入作为模型的输入表示,使得序列中所有标记能够同时处理。与基于RNN的Seq2Seq模型不同,后者由于其递归结构必须按顺序处理输入,Transformer直接对嵌入进行并行操作。每个标记的嵌入独特地捕捉了语义含义,使得自注意力机制能够在整个序列中并行地关联各个标记。这种同时进行的标记级交互消除了递归模型中固有的逐步依赖,实现了所有标记计算的完全并行化。
然而,去除显式的序列结构引入了一个新的挑战:Transformer 模型缺乏对输入序列顺序的感知,也称为“排序”问题。在RNN中,顺序得以保留是由于其序列处理的本质。为了弥补这一点,Transformer 引入了位置编码,这是一种将关于 token 的相对或绝对位置的信息直接注入到其嵌入表示中的机制,如图5c所示。这些编码在被自注意力层处理之前被添加到输入嵌入表示中,以确保模型能够根据 token 在序列中的位置来区分它们。位置编码可以通过固定的正弦函数或可学习的嵌入表示来实现,这两种方法都允许模型捕捉序列顺序,同时保持并行计算的能力。
这种基于嵌入的输入表示和位置编码的结合,使Transformer能够建模长距离依赖关系,同时充分利用并行计算。因此,与基于RNN的模型相比,Transformer架构实现了更高的性能和可扩展性。它已经成为几乎所有现代大规模语言模型和序列建模任务的基础。
自注意力机制与专家混合:增强序列理解
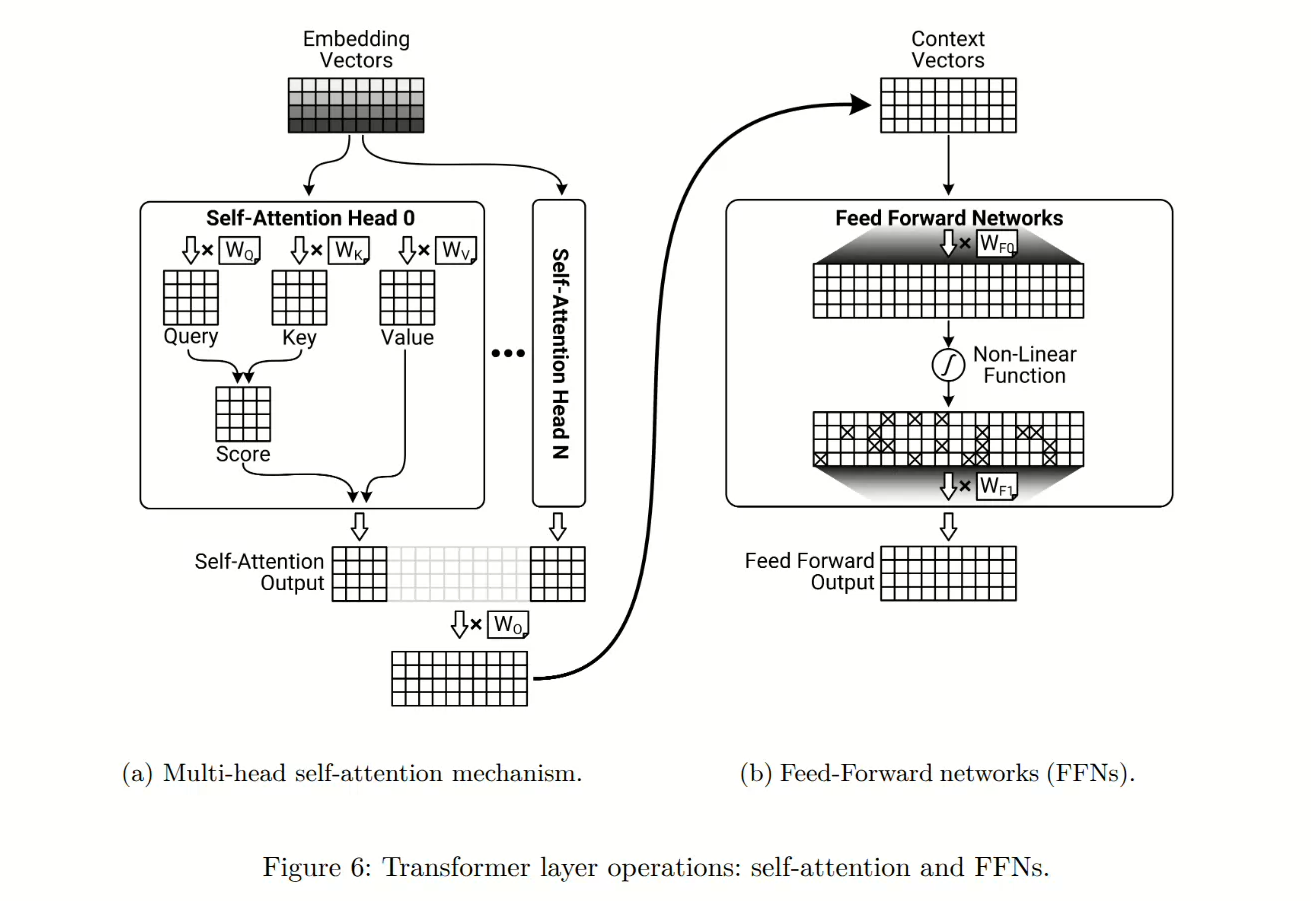
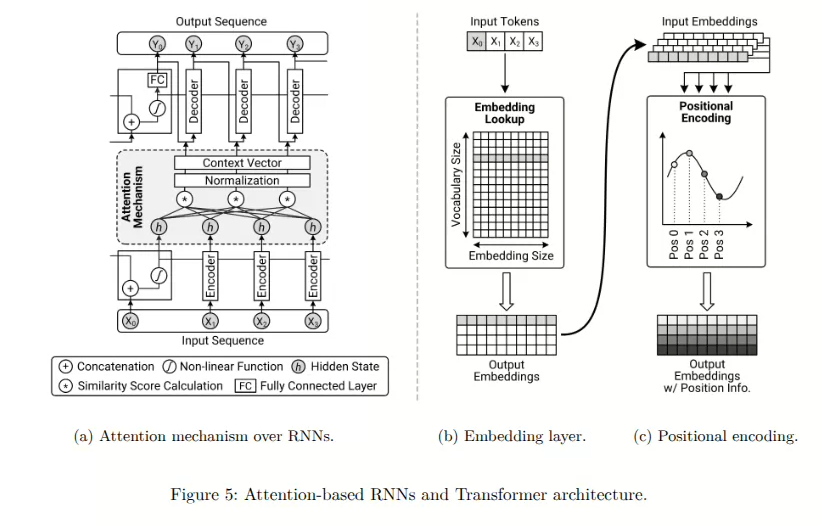
自注意力机制是Transformer架构的基石,使模型能够同时关联序列中不同部分的信息。与传统的注意力机制不同,传统的注意力机制通常对独立的输入输出序列进行对齐,而自注意力直接计算单个序列内标记之间的交互。如图6a所示,这种序列内的交互是通过三个不同的向量来实现的,即查询向量(query)、键向量(key)和值向量(value)。每个向量通过可学习的参数矩阵($W_Q$、$W_K$和$W_V$)进行独立的线性变换,从各个标记的嵌入表示中导出。具体来说,查询向量(Q)表示每个标记所寻求的信息,键向量(K)表示每个标记提供的信息,而值向量(V)则封装了标记共享的实际内容。自注意力过程涉及将每个查询向量与所有键向量通过缩放的点积操作进行比较,生成反映标记相似性或相关性的注意力分数。这些分数通过键向量维度的平方根进行缩放,以确保训练过程中的数值稳定性,并通过softmax函数进行归一化,得到注意力权重。每个标记的上下文感知表示随后通过所有值向量的加权和计算得到,权重由这些注意力分数决定。
Transformer架构通过多头注意力机制(或分组查询注意力机制)进一步增强了表示能力,在这种机制中,多个并行的自注意力计算(头)同时进行。每个注意力头使用独立的参数矩阵来生成不同的查询、键和值向量,使模型能够同时捕捉多种关系和细致的 token 交互。这种多头设计扩展了模型捕捉复杂和长距离依赖关系的能力,从而在不受到序列处理限制的情况下提升了整体模型的准确性和上下文理解能力。
这段话解释了多头注意力如何让Transformer高效处理prompt的上下文。多头设计的并行计算和token间全连接交互,使prompt处理(尤其是Prefill阶段)高度依赖计算资源(FLOPs),而非内存或I/O。
- Transformer的核心是注意力机制(attention),多头注意力(multi-head)是将单一注意力计算拆分成多个独立“头”(heads),每个头使用独立的参数矩阵(weights)来处理查询(Query)、键(Key)和值(Value)向量。
- “分组查询注意力(Grouped Query Attention, GQA)”:是多头注意力的变体(如Llama-2中使用),它将查询分组,减少计算量但保留多头优势。
- “并行的自注意力计算”:每个头独立运行自注意力公式,捕捉不同类型的关系(如一个头关注语法,另一个关注语义)。
此外,如图6b所示,Transformer在其架构中加入了专门的前馈网络(FFN),这与经典神经网络中通常提到的全连接层(FC层)有所不同。虽然自注意力机制能够捕捉标记之间的上下文关系,但每个标记的表示仍需要进一步 refinement(精炼)。为此,FFN对每个标记的嵌入独立应用独立的、位置方面的非线性变换,从而补充自注意力机制。具体来说,每个FFN包含两个线性变换,中间由一个非线性激活函数(例如ReLU或GELU)分隔。第一个线性变换将输入嵌入投影到一个“更高”维度的表示空间,使模型能够捕捉复杂的非线性数据模式。第二个线性层随后将这些精炼后的表示投影回“原始”维度空间。因此,FFN增强了自注意力机制生成的上下文感知嵌入。由于这些FFN层在每个标记位置上独立操作,它们保持了Transformer架构所特有的内在并行处理优势。
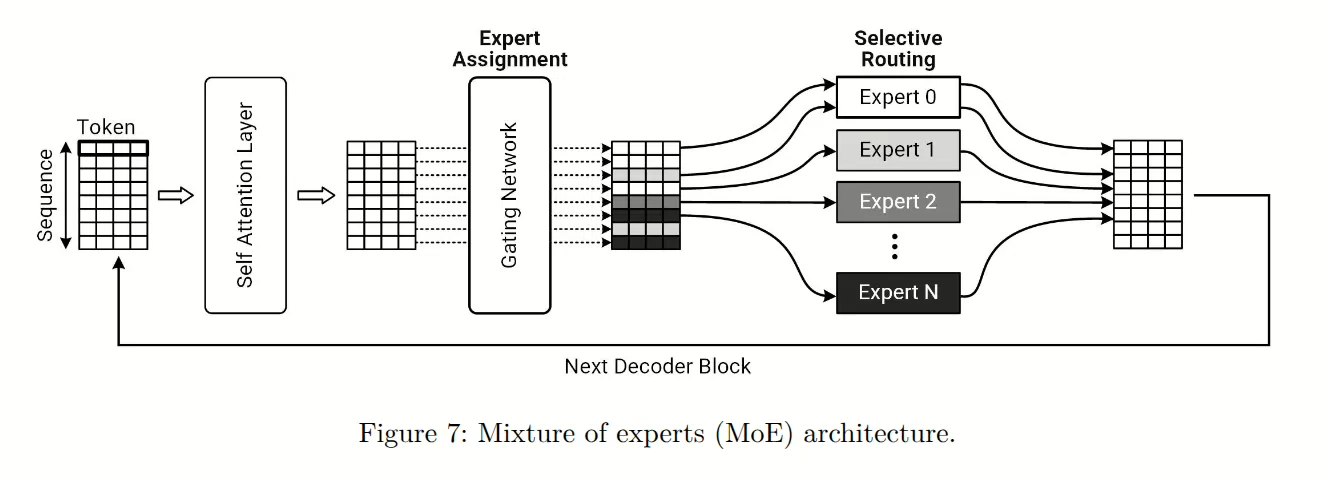
尽管FFN(前馈神经网络)对自注意力机制生成的 token 级别表示进行了精炼,但要进一步提升处理多样化和复杂数据的能力,仍需要增加模型的容量和计算效率。为了解决这一问题,Transformer 引入了诸如 Mixture of Experts (MoE,专家混合) 架构等高级结构。图7展示了 MoE 的概况,其设计目的是增强模型的容量和效率。MoE 模型由多个专门的神经网络组成,这些网络被称为专家,每个专家都被训练用于处理不同的数据类型或模式。在推理过程中,一个门控网络会根据学习到的模式将输入的 token 动态路由到选定的专家,仅激活必要的专家以优化计算资源。这种选择性激活专家的方式不仅提升了计算效率,还通过让专家专门处理特定子任务来提高模型精度。因此,基于 MoE 的 Transformer 在面对大规模和多样化数据集时,能够实现高可扩展性、鲁棒性和泛化能力,使它们在这些场景中非常有效。
需要注意的是,MoE(混合专家模型)通过多个独立专家的并行处理实现了高计算效率,但聚合这些专家的中间输出需要大量的专家间通信。此外,由于聚合后的MoE输出作为后续层(如自注意力机制)的输入,因此存在顺序依赖关系;自注意力机制必须在MoE聚合完成后才能开始处理。因此,高效的人工智能基础设施设计必须包括高速互连,以促进快速通信并支持这种必不可少的顺序处理流程。