
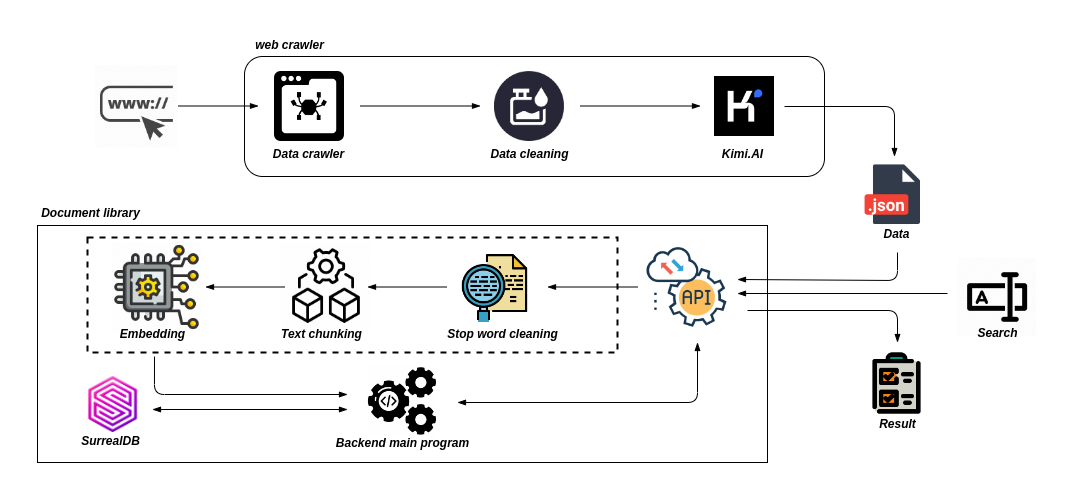
写在前面
评估信息检索系统或搜索引擎性能时使用的两个关键指标是准确度和召回率。准确度衡量检索结果的准确性,而召回率衡量查询结果的完整性或全面性。也就是说:
精确度 = 检索到的相关文档数量 / 检索到的总文档数量
召回率 = 检索到的相关文档数量 / 语料库中的总相关文档数量
高精度意味着系统能够成功返回大部分相关结果并最小化误报,而高召回率意味着系统能够找到相当比例的相关文档,从而减少漏报或错过重要文档的情况。
精确度-召回率权衡
当人们使用信息检索系统时,他们可能会遇到一个被称为“精确度-召回率权衡”的概念。这涉及到精确度和召回率之间的微妙平衡,这在信息检索中构成了一个重大挑战。
提高准确性意味着在检索文档时更加挑剔,这可能会导致漏掉一些相关文档(降低召回率)。相反,提高召回率意味着检索更多的文档,包括一些不相关的文档(降低准确性)。
通过 LLM 提高召回率和精准度
将 LLM 整合到信息检索系统中可以通过多种方式提高召回率和精确度。
自然语言理解、语义搜索和上下文查询扩展
通过要求一个LLM 扩展搜索,我们将一个自然语言短语解析成一组术语和同义词,并从这些术语和同义词中构建了一个布尔查询,该查询可以在图像底部看到。LLM“理解”搜索上下文并创建一个查询,这应该能提高准确性和召回率。

实体识别
LLMs可以从文档和查询中识别和提取实体(例如,姓名、日期、地点),通过允许更具体和准确的搜索,提高精确度和召回率
查询(重新)构建
如果初始搜索查询没有得到满意的结果,语言模型可以建议替代查询或重新构思现有查询,通过帮助用户探索不同的搜索途径来提高召回率。
两阶段检索
Retrieval Augmented Generation (RAG)
“Retrieval Augmented Generation (RAG) 是一个含义多重的术语。它承载了非常多的想像,但在开发了一个 RAG 流程之后,我们中的许多人都在想为什么它的效果没有我们预期的那么好。”
和大多数工具一样,RAG 在使用上很容易,但很难掌握。事实上,RAG 不仅仅是将文档放入向量数据库并在其上添加一个 LLM 那么简单。这样做可能有效,但并不总是如此。
在进入解决方案之前,让我们先讨论一下问题。使用RAG,我们正在对许多文本文档进行语义搜索 - 这些文档可能是数以万计甚至数以十亿计的文档。
为了确保在大规模情况下快速搜索,我们通常使用向量搜索。也就是说,我们将文本转换为向量,将它们放入向量数据库中,并使用余弦相似度等相似度度量来比较它们与查询向量的接近程度。
要进行向量搜索,我们需要向量。这些向量实质上是将一些文本的“含义”压缩成(通常是)768维或1536维的向量(OpenAI Embedding 模型可以将文本解析为1536个维度)。由于我们将这些信息压缩到一组向量中,所以会有一定的信息损失。
由于信息损失,我们经常看到根据参数返回的向量搜索文档会遗漏相关信息。也会造成低于 top_k 截止值的相关信息被检索返回。
但如果较低位置的相关信息确实可以帮助 LLM 更好的制定响应,那应该怎么办?最简单的方法是增加返回的文档数量(增加top_k),并将它们全部传递给 LLM。
但不幸的是,我们无法返回所有内容。LLM 对传递给它们的文本长度进行了限制,这称之为上下文窗口。也有一些 LLM 具有庞大的上下文窗口,比如 Anthropic 的 Claude,上下文窗口为 100K token。使用这个窗口,我们可以输入很多页的文本内容。那么我们可以返回许多文档(并非全部)并“填充”上下文窗口以提高召回率吗?
《Lost in the Middle: How Language Models Use Long Contexts》- 尽管最近的语言模型能够接受较长的上下文作为输入,但对于它们如何有效利用更长的上下文,我们了解甚少。我们分析了 LLM 的两种“需要在输入上下文中识别相关信息”任务的性能:多文档问答和键值检索。我们发现,当改变相关信息的位置时,性能可能会显著下降,这表明当前的语言模型在长输入上下文中并不稳健的利用信息。特别是,我们观察到,当相关信息出现在输入上下文的开头或结尾时,性能往往最高。而当 LLM 必须在长上下文的中间位置访问相关信息时,性能会显著下降。即使对于明确的长上下文 LLM 也是如此。
随着我们在上下文窗口中增加更多的内容,LLM的召回率会下降。当我们填充上下文窗口时,LLM 也不太可能遵循指令,因此上下文填充并不是一个很好的办法。
解决这个问题的思路是:通过检索大量的文档来最大化检索的召回率,然后通过最小化传递给 LLM 的文档数量,来最大化 LLM 的召回率。为了实现这一点,需要重新排序检索到的文档,并只保留最相关的文档供 LLM 使用,这就是我们使用重新排序(reranking)的方法。
重新排序(Rerankers)
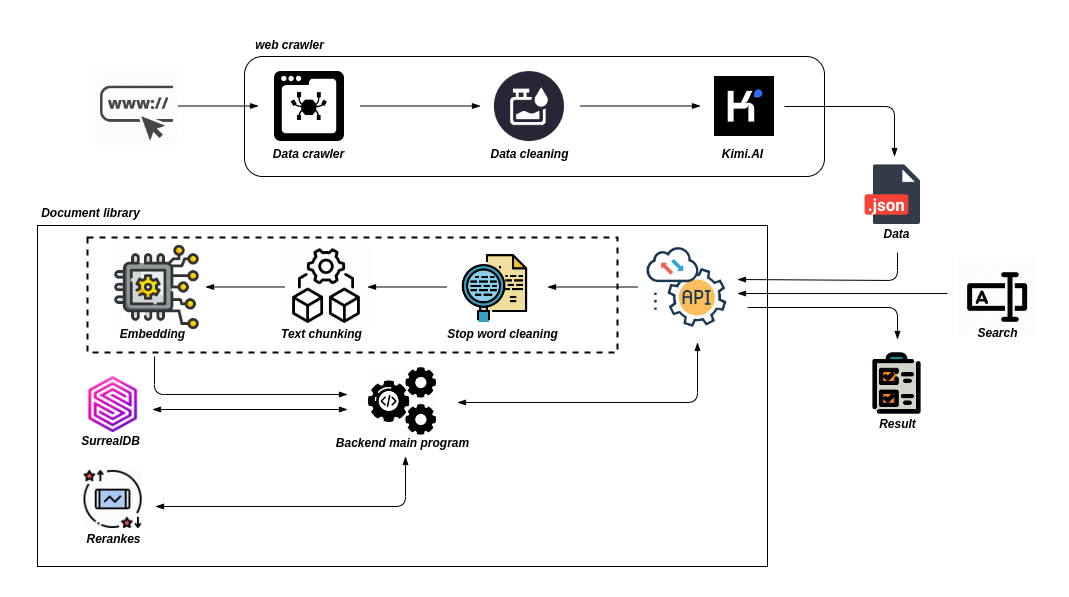
重新排序模型(也称为交叉编码器)是一种模型。给定查询内容和需要匹配的文档,它将输出一个相似度分数。我们使用这个分数来按照与查询的相关性重新排序文档。
在两阶段检索系统中使用重新排序模型时,第一阶段模型(嵌入模型/检索器)从一个较大的数据集中检索一组相关文档。然后,第二阶段模型(重新排序模型)用于对第一阶段模型检索到的文档进行重新排序。
为什么使用两个阶段?是因为从 “大型数据集中检索一小部分文档” 比 “重新排序一大部分文档” 要快得多。简单来说,重新排序的速度很慢,而检索的速度很快。
为什么要重新排序?
如果重新排序器速度如此之慢,为什么还要使用它呢?答案是,Reranker 模型比 Embedding 模型更准确。
Embedding 准确率较低的直观原因是,Embedding 模型必须将文档的所有可能含义压缩成向量,这意味着可能会丢失一部分信息。
另一方面,Reranker 模型可以直接将原始信息传递给 Transformer 计算,从而减少信息损失。由于我们在用户查询时运行 Reranker 模型,因此我们还可以分析与用户查询特定相关的文档含义,而不是试图生成一个通用的、平均的含义。
但也正因为 Reranker 避免了 Embedding 的信息损失,导致付出了其他代价 —— 时间
两阶段检索的优势
使用 Embedding 模型和向量搜索时,我们将所有繁杂的 Transformer 计算前置到了创建初始向量时。也就是说,当用户检索信息时,已经创建了向量并存储在向量数据库中,所以我们只需要做的是:
运行单个 Transformer 计算来创建查询向量。
使用余弦相似度(或其他轻量级度量)将查询向量与文档向量进行比较。
重新排序后,我们可以获得更多的相关信息。也自然而然的显著提高 RAG 的性能。这意味着我们在最大限度地增加相关信息的同时,也最大限度地减少了输入 LLM 的噪音。