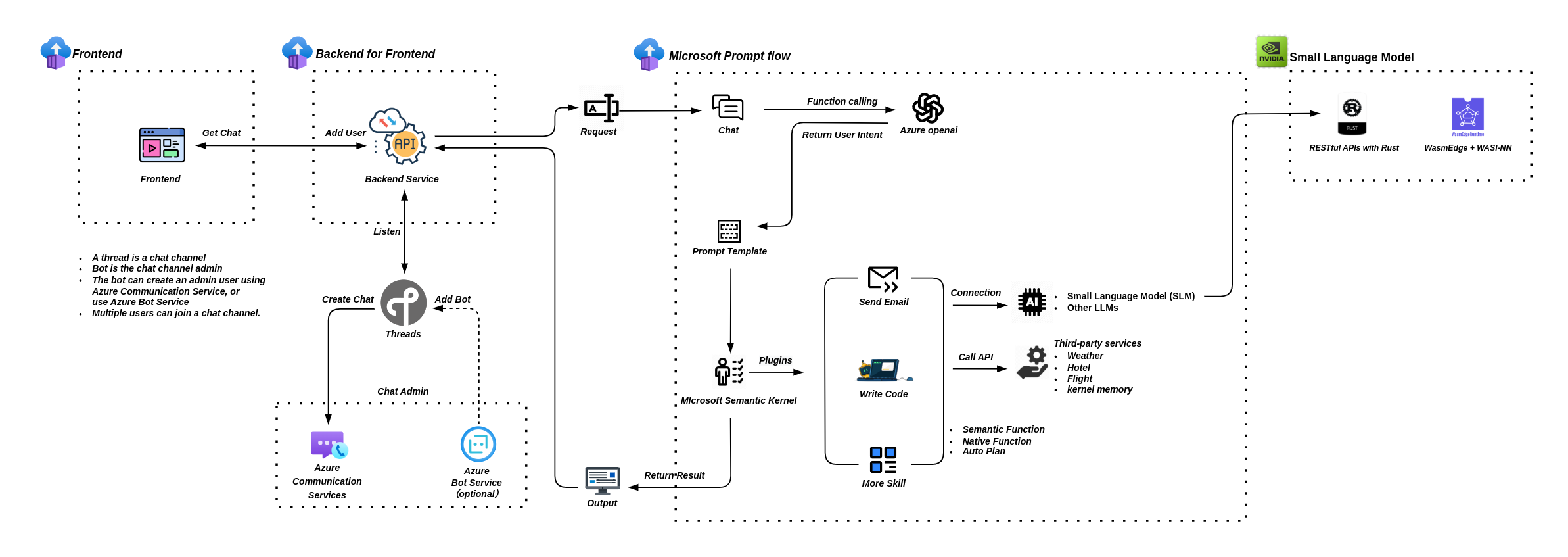
一直以来我都在尝试利用 Microsoft Promptflow 来实现大模型和小模型的协同工作,但在云端利用昂贵的GPU来运行小模型并不是我最终的想法,于是便开始尝试使用本地GPU,甚至是CPU来进行小模型的推理。很有意思的是有很多人和我的想法一致,于是我整理了以下一些资料。
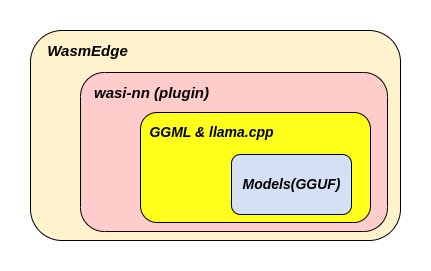
WasmEdge + WASI-NN plug-in
WasmEdge 是一个轻量级、高性能、可扩展的WebAssembly运行时,适用于云原生、边缘和去中心化应用。它支持无服务器应用、嵌入式函数、微服务、用户定义函数、智能合约和物联网设备。WasmEdge目前是CNCF(云原生计算基金会)的沙盒项目。WasmEdge运行时为其包含的WebAssembly字节码程序提供了一个明确定义的执行沙箱。运行时为操作系统资源(例如文件系统、套接字、环境变量、进程)和内存空间提供隔离和保护。
WASI-NN 插件是用于机器学习的WebAssembly系统接口(WASI)API,它允许WebAssembly程序访问主机提供的机器学习功能。
GGML&llama.cpp 是一套专注于机器学习的C/C++库。两者都是由Georgi Gerganov创建,这就是“GG”这个缩写的含义。llama.cpp库用于高效推理Llama模型。它可以加载GGML模型并在CPU上运行。最初,这是与GPTQ模型的主要区别,后者是在GPU上加载和运行的。然而,现在你可以使用llama.cpp将一些层次的LLM转移到GPU上。
GGUF 也是由Georgi Gerganov提供的,这种新格式被设计成可扩展的,以便新功能不会破坏与现有模型的兼容性。它还将所有元数据集中在一个文件中,例如特殊标记、RoPE缩放参数等。简而言之,它解决了一些历史上的痛点,并且应该具备未来的兼容性。也可以称之为“GGML模型”,这些模型要么使用GGUF格式,要么使用之前的格式。
Rust 实际上如今大多数LLM应用程序都是用Python编写的,但Python太慢、太臃肿。事实上,LLVM、Clang和Swift的发明者Chris Lattner曾经证明Python比编译语言慢35,000倍,这就是他为什么发明了Mojo语言作为Python的替代品。这迫使开发者将越来越多的应用逻辑推向本地编译的代码,比如C、C++和Rust。例如:像llama.cpp、whisper.cpp和llama2.c这样非常受欢迎的项目,都是不依赖Python的。换句话说,Python不仅非常慢,而且难以用于开发LLM应用程序。
Python的挑战为高性能编译语言创造了机会。随着C和C++在开发者社区中失去对Rust的竞争力,Rust便脱颖而出。然而,直接将Rust编译为本机机器代码还存在其他问题:
安全性:本地二进制文件可能会导致整个系统崩溃
可移植性:本地二进制文件特定于底层操作系统和硬件。
最重要的性能:由于安全性和可移植性要求,通常需要在Linux容器中运行本机二进制文件。这些容器会给程序增加启动和运行时的开销,从而大大降低其速度。
因此,Wasm已成为Rust应用程序的主要安全运行时,以解决这些问题。借助面向云优化的Wasm运行时WasmEdge,开发人员现在可以选择在LLM应用程序堆栈的每一层中使用高性能的Rust,作为Python的高性能替代方案。
针对以上问题,使用Rust + Wasm不仅代替Python以提升性能,还从根本上减少占用空间,并提高安全性。
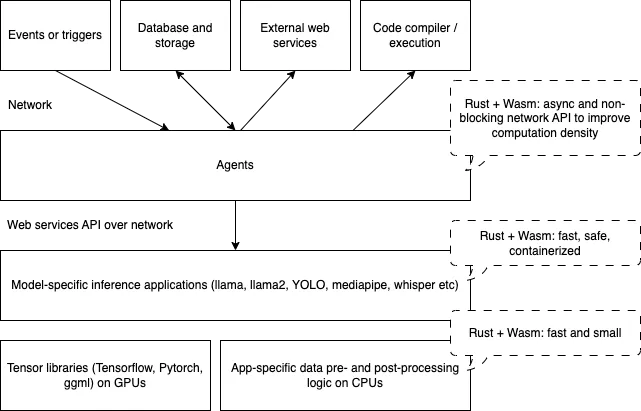
Agent layer: 用于接收互联网事件、连接数据库和调用其他网络服务的网络密集型任务。Rust和WasmEdge为高密度和高性能的代理应用程序提供异步和非阻塞的I/O。Inference layer: 将数据(例如单词和句子)预处理为数字,并将数字后处理为句子或结构化的JSON数据的CPU密集型任务。这些功能可以使用Rust编写,以实现最佳性能,并在WasmEdge中运行以实现安全性和可移植性。Tensor layer: 将需要大量GPU计算的任务从Wasm传递给本地张量库,如llama.cpp、PyTorch和Tensorflow,通过WasmEdge的WASI-NN插件。
由此可见,Rust和Wasm可能是今天对Python来说高性能且对开发者友好的替代品
安装 WasmEdge 安装WasmEdge有两种方式:
1、直接安装编译好的二进制文件
通过命令行可以直接安装WasmEdge以及WASI-NN插件。
1 curl -sSf https://raw.githubusercontent.com/WasmEdge/WasmEdge/master/utils/install.sh | bash -s -- --plugins wasi_nn-ggml
这样的好处就是非常简单,安装完成即可使用。当然也有不好的地方,因为插件的后端是依赖GGML&llama.cpp的C/C++库,如果C/C++库更新并支持了新模型,但插件并没有及时更新的话,就会导致无法使用C/C++库所兼容的新模型,需要等待开源项目更新插件。
2、手动构建WasmEdge
通过源代码手动构建WasmEdge可以解决上一个问题。具体构建过程可以在WasmEdge的官方文档 找到。但如果使用一台全新的虚拟机来构建编译环境,还是非常复杂的一件事。
首先要创建一台带有GPU的虚拟机,因为构建过程需要用到 CUDA,但并不需要高性能的GPU型号,我直接选择了T4。另外,如果是跑一些像是 llama2-7b,或者是microsoft Phi2这种的小模型,32G内存就可以满足,如果内存太小会影响到 ctx-size 所需的内存空间,导致推理失败。最后还是建议将虚拟机创建在海外,这样便于获取资源。我在Azure的日本区域创建了一台NC8as_T4_v3型号的8核56G内存,带有一块NVIDIA T4 GPU的虚拟机。
虚拟机创建好之后的第一件事还是安装GPU驱动
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 sudo apt-get install alsa-base alsa-utils sudo apt install ubuntu-drivers-common ubuntu-drivers devices == /sys/devices/pci0000:00/0000:00:0d.0 == modalias : pci:v000010DEd00001EB8sv000010DEsd000012A2bc03sc02i00 vendor : NVIDIA Corporation model : TU104GL [Tesla T4] driver : nvidia-driver-470-server - distro non-free driver : nvidia-driver-418-server - distro non-free driver : nvidia-driver-535 - distro non-free recommended driver : nvidia-driver-535-server - distro non-free driver : nvidia-driver-470 - distro non-free driver : nvidia-driver-525 - distro non-free driver : nvidia-driver-525-server - distro non-free driver : nvidia-driver-450-server - distro non-free driver : xserver-xorg-video-nouveau - distro free builtin sudo apt install nvidia-driver-535 sudo reboot nvidia-smi Mon Feb 5 10:09:15 2024 +---------------------------------------------------------------------------------------+ | NVIDIA-SMI 535.154.05 Driver Version: 535.154.05 CUDA Version: 12.2 | |-----------------------------------------+----------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+======================+======================| | 0 Tesla T4 Off | 00000000:00:0D.0 Off | 0 | | N/A 44C P8 11W / 70W | 6MiB / 15360MiB | 0% Default | | | | N/A | +-----------------------------------------+----------------------+----------------------+ +---------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=======================================================================================| | 0 N/A N/A 1322 G /usr/lib/xorg/Xorg 4MiB | +---------------------------------------------------------------------------------------+
驱动装好之后,还需要安装CUDA
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 wget https://developer.download.nvidia.com/compute/cuda/12.2.2/local_installers/cuda_12.2.2_535.104.05_linux.run sudo sh cuda_12.2.2_535.104.05_linux.run ┌──────────────────────────────────────────────────────────────────────────────┐ │ Existing package manager installation of the driver found. It is strongly │ │ recommended that you remove this before continuing. │ │ Abort │ │ Continue │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ Up/Down: Move | 'Enter' : Select │ └──────────────────────────────────────────────────────────────────────────────┘ ┌──────────────────────────────────────────────────────────────────────────────┐ │ End User License Agreement │ │ -------------------------- │ │ │ │ NVIDIA Software License Agreement and CUDA Supplement to │ │ Software License Agreement. Last updated: October 8, 2021 │ │ │ │ The CUDA Toolkit End User License Agreement applies to the │ │ NVIDIA CUDA Toolkit, the NVIDIA CUDA Samples, the NVIDIA │ │ Display Driver, NVIDIA Nsight tools (Visual Studio Edition), │ │ and the associated documentation on CUDA APIs, programming │ │ model and development tools. If you do not agree with the │ │ terms and conditions of the license agreement, then do not │ │ download or use the software. │ │ │ │ Last updated: October 8, 2021. │ │ │ │ │ │ Preface │ │ ------- │ │ │ │──────────────────────────────────────────────────────────────────────────────│ │ Do you accept the above EULA? (accept/decline/quit): │ │ accept │ └──────────────────────────────────────────────────────────────────────────────┘ ┌──────────────────────────────────────────────────────────────────────────────┐ │ CUDA Installer │ │ - [ ] Driver │ │ [ ] 535.104.05 │ │ + [X] CUDA Toolkit 12.2 │ │ [X] CUDA Demo Suite 12.2 │ │ [X] CUDA Documentation 12.2 │ │ - [ ] Kernel Objects │ │ [ ] nvidia-fs │ │ Options │ │ Install │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ Up/Down: Move | Left/Right: Expand | 'Enter' : Select | 'A' : Advanced options │ └──────────────────────────────────────────────────────────────────────────────┘ =========== = Summary = =========== Driver: Not Selected Toolkit: Installed in /usr/local/cuda-12.2/ Please make sure that - PATH includes /usr/local/cuda-12.2/bin - LD_LIBRARY_PATH includes /usr/local/cuda-12.2/lib64, or, add /usr/local/cuda-12.2/lib64 to /etc/ld.so.conf and run ldconfig as root To uninstall the CUDA Toolkit, run cuda-uninstaller in /usr/local/cuda-12.2/bin ***WARNING: Incomplete installation! This installation did not install the CUDA Driver. A driver of version at least 535.00 is required for CUDA 12.2 functionality to work. To install the driver using this installer, run the following command , replacing <CudaInstaller> with the name of this run file: sudo <CudaInstaller>.run --silent --driver
修改环境变量验证CUDA是否安装成功
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 sudo vim ~/.bashrc export PATH=/usr/local/cuda-12.2/bin${PATH:+:${PATH} } export LD_LIBRARY_PATH=/usr/local/cuda-12.2/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH} } source ~/.bashrcnvcc --version nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2023 NVIDIA Corporation Built on Tue_Aug_15_22:02:13_PDT_2023 Cuda compilation tools, release 12.2, V12.2.140 Build cuda_12.2.r12.2/compiler.33191640_0
到这里就可以直接选择 方式1 来安装WasmEdge,如果选择 方式2 还需要再做一些准备工作。
首先要更新cmake,WasmEdge对cmake有版本要求,系统自带的cmake通常版本都很低,所以要手动更新到高版本。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 sudo apt-get install libssl-dev sudo apt remove cmake wget https://github.com/Kitware/CMake/releases/download/v3.28.1/cmake-3.28.1.tar.gz tar xf ./cmake-3.28.1.tar.gz cd cmake-3.28.1/./bootstrap sudo make sudo make install sudo ln -s /usr/local/bin/cmake /usr/bin sudo cmake --version
除了cmake之外,WasmEdge还依赖 LLVM 和 LLD 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 sudo git clone https://github.com/llvm/llvm-project llvm-project mkdir build && cd buildsudo cmake -DLLVM_ENABLE_BINDINGS=Off -DLLVM_BUILD_DOCS=Off -DCMAKE_BUILD_TYPE=Release -DLLVM_ENABLE_PROJECTS=lld -DCMAKE_INSTALL_PREFIX=/usr/local -G "Unix Makefiles" ../llvm-project/llvm sudo make install
接下来就可以开始构建安装WasmEdge了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 sudo apt-get install -y ninja-build git clone https://github.com/WasmEdge/WasmEdge.git cd WasmEdge/export CXXFLAGS="-Wno-error" export CUDAARCHS="60;61;70" sudo cmake -GNinja -Bbuild -DCMAKE_BUILD_TYPE=Release \ -DCMAKE_CUDA_ARCHITECTURES="60;61;70" \ -DCMAKE_CUDA_COMPILER=/usr/local/cuda/bin/nvcc \ -DWASMEDGE_PLUGIN_WASI_NN_BACKEND="GGML" \ -DWASMEDGE_PLUGIN_WASI_NN_GGML_LLAMA_BLAS=OFF \ -DWASMEDGE_PLUGIN_WASI_NN_GGML_LLAMA_CUBLAS=ON \ . sudo cmake --build build sudo cmake --install build -- Install configuration: "Release" -- Installing: /usr/local/lib/libwasmedge.so.0.1.0 -- Installing: /usr/local/lib/libwasmedge.so.0 -- Set non-toolchain portion of runtime path of "/usr/local/lib/libwasmedge.so.0.1.0" to "$ORIGIN " -- Installing: /usr/local/lib/libwasmedge.so -- Installing: /usr/local/include/wasmedge/wasmedge.h -- Installing: /usr/local/include/wasmedge/version.h -- Installing: /usr/local/include/wasmedge/enum.inc -- Installing: /usr/local/include/wasmedge/enum_configure.h -- Installing: /usr/local/include/wasmedge/enum_errcode.h -- Installing: /usr/local/include/wasmedge/enum_types.h -- Installing: /usr/local/include/wasmedge/int128.h -- Installing: /usr/local/lib/cmake/Llama/LlamaConfig.cmake -- Installing: /usr/local/lib/cmake/Llama/LlamaConfigVersion.cmake -- Installing: /usr/local/include/ggml.h -- Installing: /usr/local/include/ggml-alloc.h -- Installing: /usr/local/include/ggml-backend.h -- Installing: /usr/local/include/ggml-cuda.h -- Installing: /usr/local/lib/libllama.a -- Installing: /usr/local/include/llama.h -- Installing: /usr/local/bin/convert.py -- Installing: /usr/local/bin/convert-lora-to-ggml.py -- Installing: /usr/local/include/simdjson.h -- Installing: /usr/local/lib/libsimdjson.a -- Installing: /usr/local/lib/cmake/simdjson/simdjson-config.cmake -- Installing: /usr/local/lib/cmake/simdjson/simdjson-config-version.cmake -- Installing: /usr/local/lib/cmake/simdjson/simdjsonTargets.cmake -- Installing: /usr/local/lib/cmake/simdjson/simdjsonTargets-release.cmake -- Installing: /usr/local/lib/pkgconfig/simdjson.pc -- Installing: /usr/local/lib/wasmedge/libwasmedgePluginWasiNN.so -- Set non-toolchain portion of runtime path of "/usr/local/lib/wasmedge/libwasmedgePluginWasiNN.so" to "$ORIGIN " -- Installing: /usr/local/bin/wasmedgec -- Set non-toolchain portion of runtime path of "/usr/local/bin/wasmedgec" to "$ORIGIN /../lib" -- Installing: /usr/local/bin/wasmedge -- Set non-toolchain portion of runtime path of "/usr/local/bin/wasmedge" to "$ORIGIN /../lib" wasmedge --version wasmedge version 0.14.0-alpha.1-49-g92e93cdb /usr/local/lib/wasmedge/libwasmedgePluginWasiNN.so (plugin "wasi_nn" ) version 0.10.1.0
至此WasmEdge的安装就结束了
使用WasmEdge 项目组提供了一个开源项目 ,此项目基于Rust语言开发,目的是让开发者熟悉如何使用 WasmEdge & WASI-NN 开发应用。
开源项目中提供了simple、api-server、chat三种应用方式。simple暂且不说,它只是简单说明了如何调用 wasi-nn 接口。但 api-server 和 chat 在设计方面,因两者针对的使用场景不同,内部的整体设计也截然不同,但是底层的推理接口均使用的 wasi-nn 接口。只是在设计上,api-server 根据应用场景的需要,对wasi_nn::Graph 和wasi_nn::GraphExecutionContext 进行了封装,封装后的对象实例是以全局变量的形态存在,主要目的是在server启动时,就可以加载模型,从而避免用户发起对话请求时,冷启动造成的不必要等待。
为了简单测试,我直接下载项目组已经编译好的 api-server。
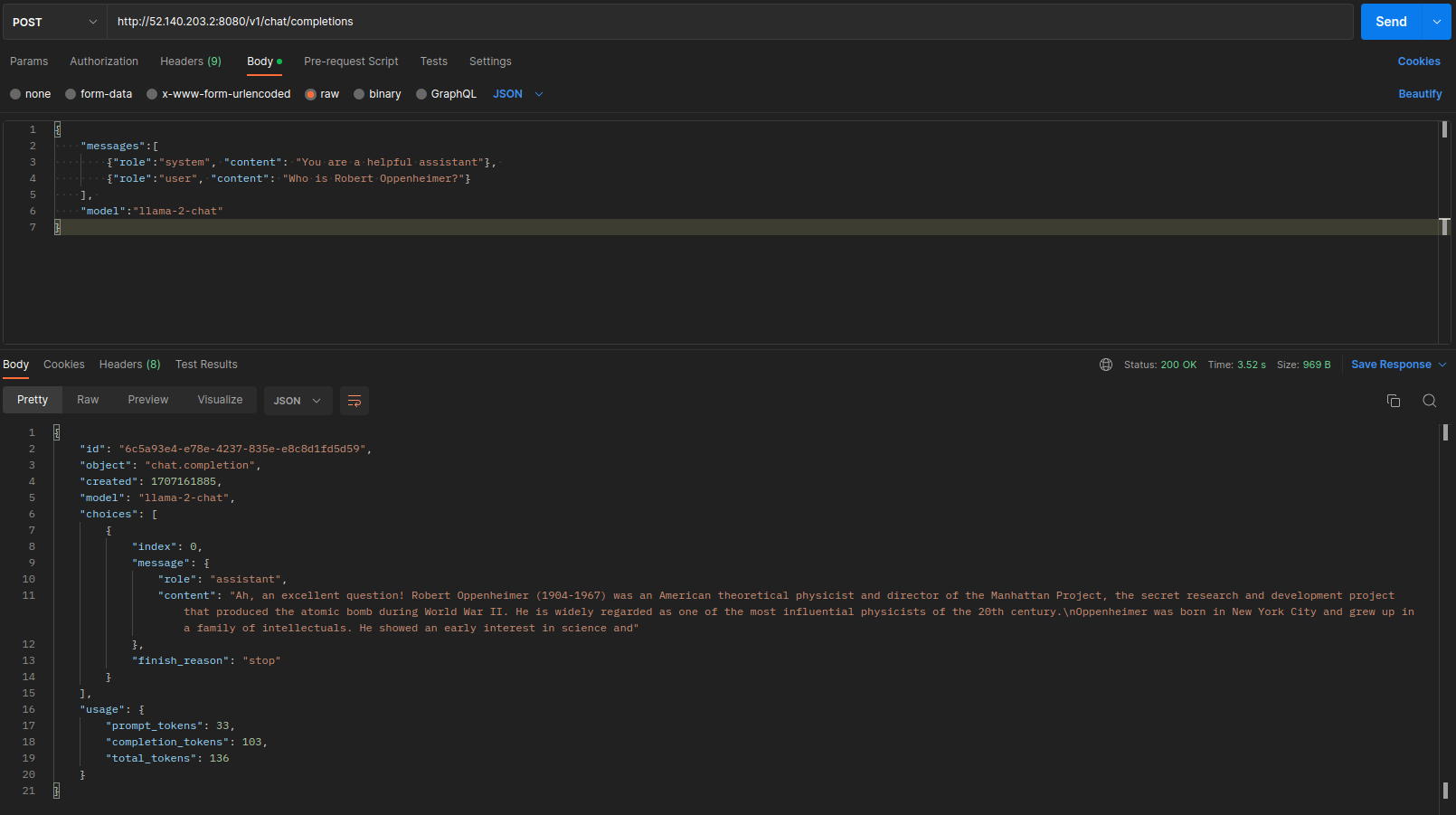
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 curl -LO https://huggingface.co/second-state/Llama-2-7B-Chat-GGUF/resolve/main/llama-2-7b-chat.Q5_K_M.gguf wget https://github.com/second-state/LlamaEdge/releases/download/0.2.14/llama-api-server.wasm wasmedge --dir .:. --nn-preload default:GGML:AUTO:llama-2-7b-chat.Q5_K_M.gguf llama-api-server.wasm -p llama-2-chat [INFO] Socket address: 0.0.0.0:8080 [INFO] Model name: default [INFO] Model alias : default [INFO] Prompt context size: 512 [INFO] Number of tokens to predict: 1024 [INFO] Number of layers to run on the GPU: 100 [INFO] Batch size for prompt processing: 512 [INFO] Temperature for sampling: 1 [INFO] Top-p sampling (1.0 = disabled): 1 [INFO] Penalize repeat sequence of tokens: 1.1 [INFO] Presence penalty (0.0 = disabled): 0 [INFO] Frequency penalty (0.0 = disabled): 0 [INFO] Prompt template: Llama2Chat [INFO] Log prompts: false [INFO] Log statistics: false [INFO] Log all information: false [INFO] Starting server ... ggml_init_cublas: GGML_CUDA_FORCE_MMQ: no ggml_init_cublas: CUDA_USE_TENSOR_CORES: yes ggml_init_cublas: found 1 CUDA devices: Device 0: Tesla T4, compute capability 7.5, VMM: yes [INFO] Plugin version: b2037 (commit 1cfb5372) [INFO] Listening on http://0.0.0.0:8080
启动之后我们用postman测一下,总体来说效果不错,模型的加载速度很快,推理速度也很快。
WasmEdge的官方文档中还提供了一部分在 Nvidia Jetson 中构建WasmEdge的说明,其实这部分才是我真正需要的内容,而且已经在我的 Jetson 环境中测试成功了。现在我可以重新修改应用架构,并将SLM(Small Language Model)加入到应用环境中。但如果要想让小模型发挥真正的作用,还需要做更多的工作。例如:选择更优秀的基础模型、重新调整prompt并针对prompt指令微调模型、针对RAG对需要检索的数据进行分类存储等等。